








技術(shù)專欄
玩轉(zhuǎn)uniprot數(shù)據(jù)庫(kù)
 供稿:技術(shù)部
供稿:技術(shù)部 發(fā)布時(shí)間:2022-06-07
發(fā)布時(shí)間:2022-06-07 瀏覽量:3736次
瀏覽量:3736次
一、Uniprot蛋白數(shù)據(jù)庫(kù)介紹及使用詳解
Uniprot數(shù)據(jù)庫(kù)是資源最廣屋剑、信息最豐富的蛋白質(zhì)數(shù)據(jù)庫(kù)签党,是查詢蛋白功能的首選數(shù)據(jù)庫(kù)衷恭。Uniprot數(shù)據(jù)庫(kù)由Swiss-Prot贩纵、TrEMBL和PIR-PSD三大子數(shù)據(jù)庫(kù)構(gòu)成亥鬓,數(shù)據(jù)主要來(lái)自于各物種基因組測(cè)序完成后得到的全基因蛋白質(zhì)序列符固,并包含了很多來(lái)自文獻(xiàn)中的蛋白及其功能信息谨斥。尤其是swiss-prot 子數(shù)據(jù)庫(kù)斟记,庫(kù)中蛋白質(zhì)信息都是手工核對(duì)過(guò)的 玩猿,非冗余, 有詳細(xì)注釋信息的蛋白數(shù)據(jù)盈械。作為一名科研工作者魄恭,Uniprot數(shù)據(jù)庫(kù)的使用技能應(yīng)該是必備的技能之一。
(1)UniProtKB(UniProt Knowledgebase)是蛋白質(zhì)序列案贩、功能揣褂、分類、交叉引用等信息存取中心;UniProtKB 主要由兩部分組成∶
UniProtKB/Swiss-Prot∶高質(zhì)量的攒庵、手工注釋的嘴纺、非冗余的數(shù)據(jù)集;主要來(lái)自文獻(xiàn)中的研究成果和 E-value 校驗(yàn)過(guò)計(jì)算分析結(jié)果。有質(zhì)量保證的數(shù)據(jù)才被加入該數(shù)據(jù)庫(kù);
UniProtKB/TrEMBL∶該數(shù)據(jù)集包含高質(zhì)量的計(jì)算分析結(jié)果浓冒,—般都在自動(dòng)注釋中富集栽渴,主要應(yīng)對(duì)基因組項(xiàng)目獲得的大量數(shù)據(jù)流以及人工校驗(yàn)在時(shí)間上和人力上的不足。注釋所有可用的蛋白序列稳懒。在三大核酸數(shù)據(jù)庫(kù)(EMBL-Bank/GenBank/DDBJ)中注釋的編碼序列都被自動(dòng)翻譯并加入該數(shù)據(jù)庫(kù)中闲擦。它也有來(lái)自 PDB 數(shù)據(jù)庫(kù)的序列,以及Ensembl场梆、Refeq和 CCDS基因預(yù)測(cè)的序列;
(2)UniRef(UniProt Non-redundant Reference)將密切相關(guān)的蛋白質(zhì)序列組合到一條記錄中墅冷,以便提高搜索速度。目前,根據(jù)序列相似程度形成 3個(gè)子庫(kù)寞忿,即 UniRef10 0驰唬、UniRef90和 UniRef50;
(3)UniParc(UniProt Archive)是一個(gè)綜合性的非冗余數(shù)據(jù)庫(kù),包含了所有主要的罐脊、公開(kāi)的數(shù)據(jù)庫(kù)的蛋白質(zhì)序列定嗓。由于蛋白質(zhì)可能在不同的數(shù)據(jù)庫(kù)中存在,并且可能在同一個(gè)數(shù)據(jù)庫(kù)中有多個(gè)版本萎雁,為了去幾余长恒,UniaraParc 對(duì)每條唯—的序列只存—次無(wú)論是否為同一物種的序列,只要序列相同就被合并為一條您眉,每條序列提供穩(wěn)定的北取、唯一的編號(hào) UPI。該數(shù)據(jù)庫(kù)含有蛋白質(zhì)的序列信息林皇,而沒(méi)有注釋數(shù)據(jù)涯翠。
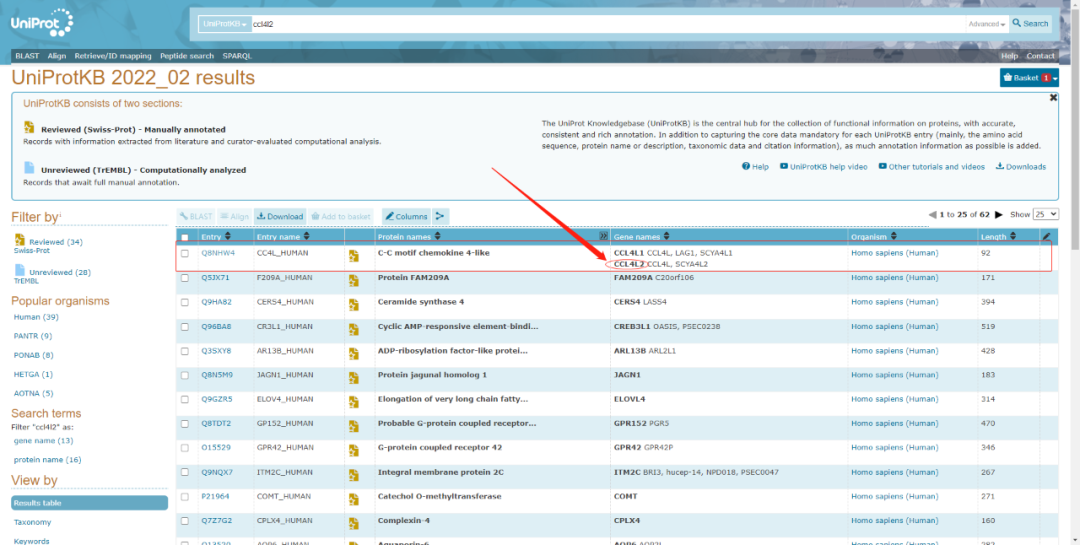
UniProt 數(shù)據(jù)庫(kù)中,UniProtKB/Swiss-Prot 是我們最常用的妓付,今天我們主要介紹這個(gè)數(shù)據(jù)庫(kù)的使用憔吉。我們?cè)谳斎霗谥休斎隒CL4L2,點(diǎn)擊search滚胎,就會(huì)出現(xiàn)不同物種該蛋白的詳細(xì)信息肿讽。找到我們想要的物種條目,點(diǎn)擊進(jìn)入田搏。
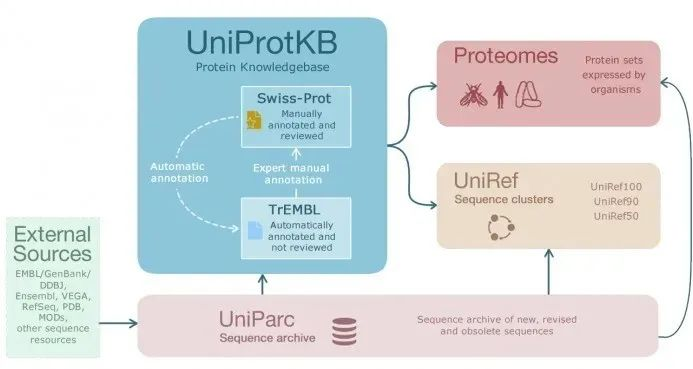
Uniprot數(shù)據(jù)庫(kù)主要子數(shù)據(jù)庫(kù)組成:
以上子數(shù)據(jù)庫(kù)間的關(guān)系如下:uniprot會(huì)收集EMBL找田,GenBank,DDBJ等公共數(shù)據(jù)庫(kù)中的蛋白質(zhì)序列及功能信息等原始數(shù)據(jù)着憨,處理后存入U(xiǎn)niParc的非冗余蛋白質(zhì)序列數(shù)據(jù)庫(kù)墩衙;UniPrc作為數(shù)據(jù)倉(cāng)庫(kù),再分別給UniProtKB甲抖,Proteomes漆改,UNIRef提供可靠的數(shù)據(jù)集,其中在UniProtKB數(shù)據(jù)庫(kù)中Swiss-Prot是由TrEMBL經(jīng)過(guò)手動(dòng)注釋后得到的高質(zhì)量非冗余數(shù)據(jù)庫(kù)准谚,也是我們最常用的蛋白質(zhì)數(shù)據(jù)庫(kù)之一挫剑。
Uniprot數(shù)據(jù)庫(kù)官方鏈接:https://www.uniprot.org/
1. 單個(gè)蛋白質(zhì)信息查詢
下圖是Uniprot官方網(wǎng)站首頁(yè),在UniprotKB欄輸入蛋白ID或Accession number氛魁,然后點(diǎn)擊search暮顺,就可以查詢蛋白功能。

我們以HUMAN CCL4L2為例秀存,搜索其在Uniprot數(shù)據(jù)庫(kù)中的信息捶码,如下圖羽氮,頁(yè)面默認(rèn)顯示Entry模式,頁(yè)面顯示內(nèi)容包括:蛋白名稱惫恼、物種來(lái)源舀美、GO功能注釋、亞細(xì)胞定位垃燃、組織特異性表達(dá)情況玉桅、互作蛋白、Domain介然、序列信息掷锻、同源蛋白以及其他數(shù)據(jù)鏈接等信息。

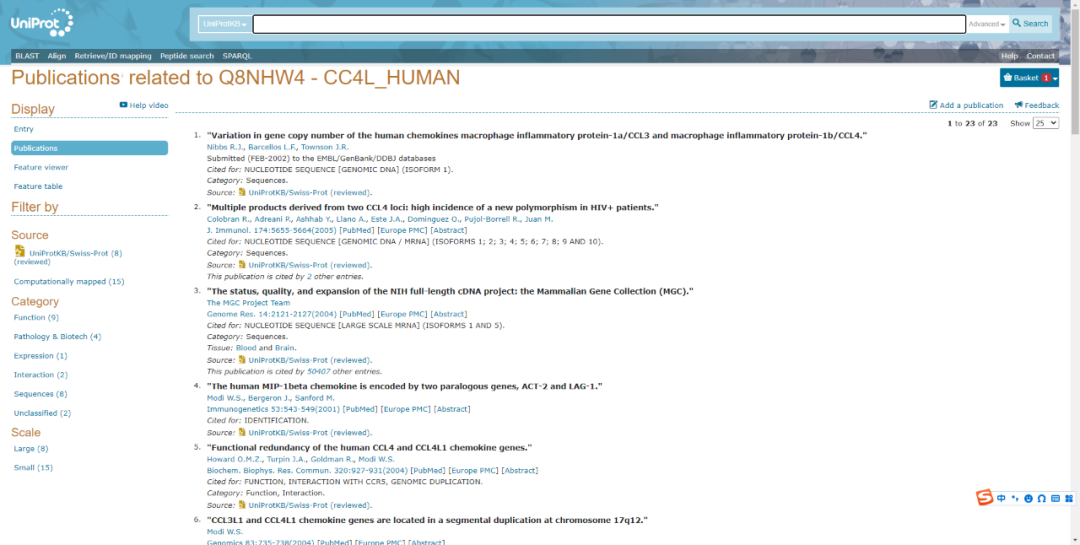
點(diǎn)擊Display下Publications按鈕盗晨,數(shù)據(jù)庫(kù)會(huì)展示該蛋白發(fā)表已經(jīng)收錄的文章蔑来。
2. 批量蛋白質(zhì)信息查詢
假如需要查詢的蛋白較多,則可以通過(guò)點(diǎn)擊首行任務(wù)欄Retrieve/ID mapping献鬼,如下圖澈虱,查詢蛋白列表可直接粘貼在下圖1. Provide your identifiers文本框中,也可以將蛋白ID單列粘貼于TXT文本中提交到網(wǎng)站许夺。另外該頁(yè)面2. Select options 還可提供ID轉(zhuǎn)換功能表牲,支持多種數(shù)據(jù)庫(kù)間的ID轉(zhuǎn)換。
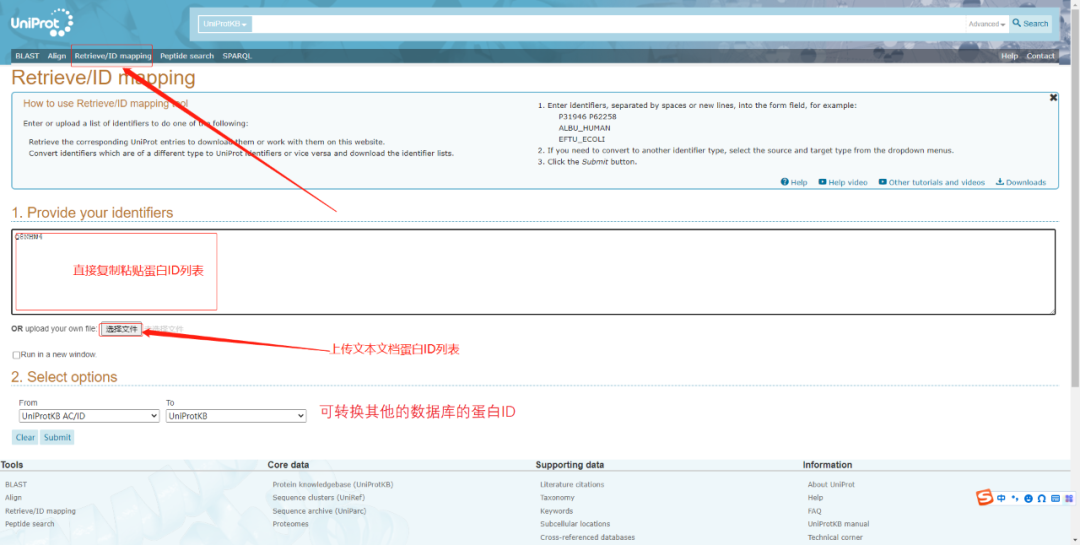
提交好蛋白列表后扼褪,點(diǎn)擊Submit想幻,網(wǎng)站便會(huì)自動(dòng)分析,結(jié)果展現(xiàn)形式如下:
展示信息包括:蛋白對(duì)應(yīng)的基因名迎捺、蛋白描述举畸、序列長(zhǎng)度等信息查排。
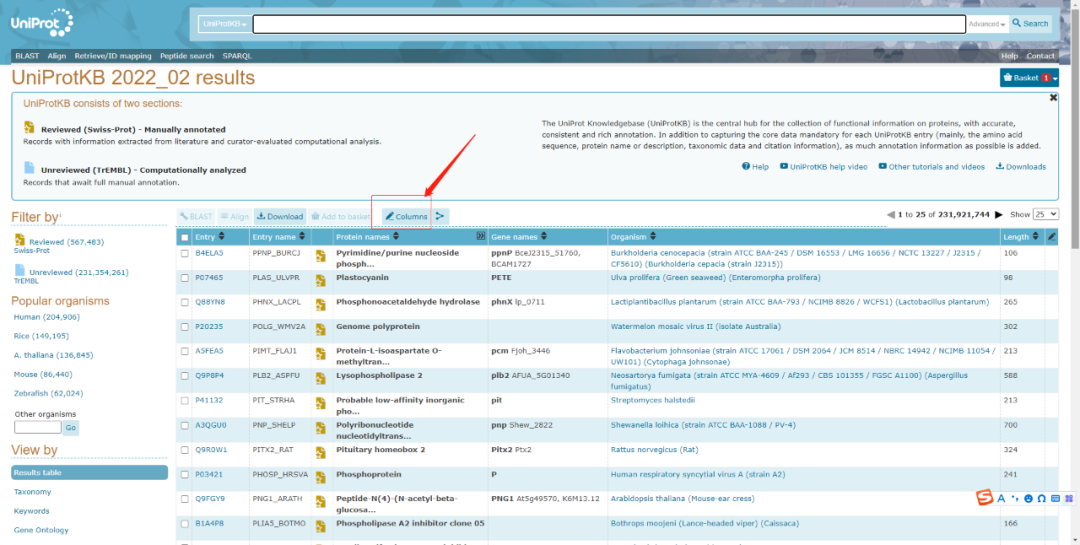
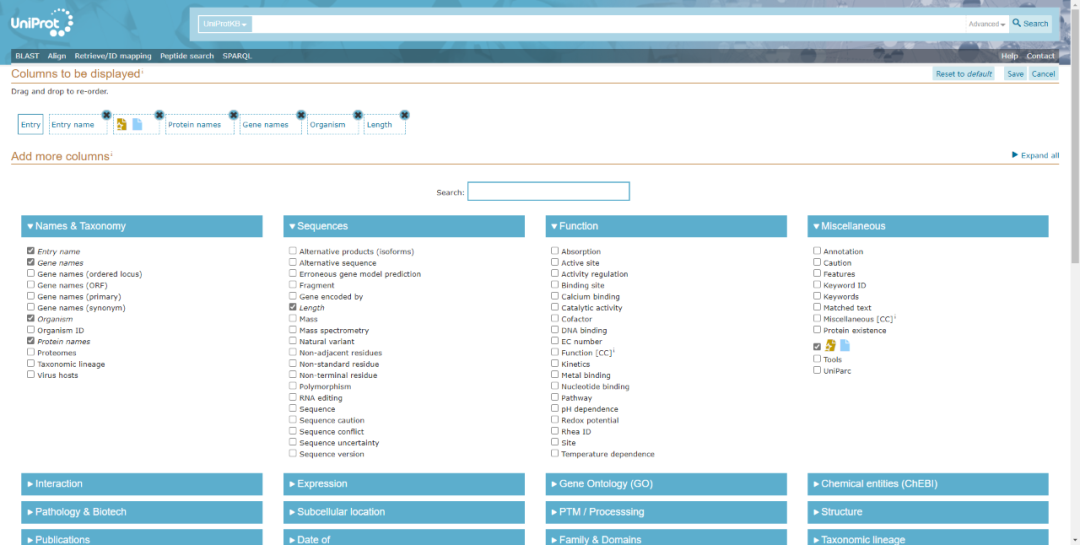
點(diǎn)擊Column按鈕凳枝,可以選擇需要展示的數(shù)據(jù)庫(kù)信息,如GO跋核、pathway岖瑰、亞細(xì)胞定位等注釋信息,如下圖砂代,選擇完畢后點(diǎn)擊save保存設(shè)置蹋订,系統(tǒng)會(huì)自動(dòng)跳轉(zhuǎn)至信息展示頁(yè)面。
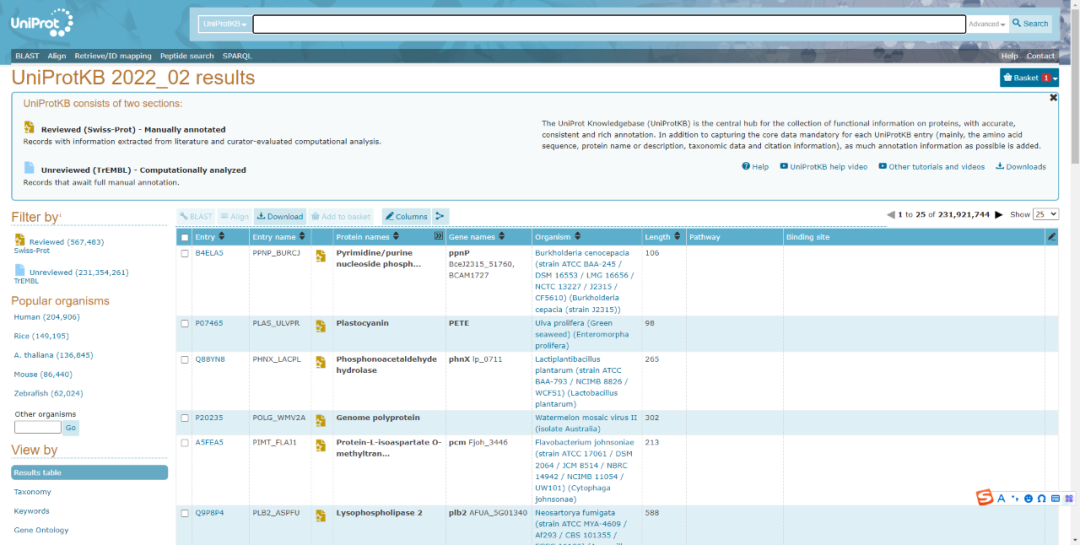
最終結(jié)果展示如下圖刻伊,勾選感興趣的蛋白露戒,即可將本次注釋結(jié)果下載到本地查看,并且支持包括Excel格式在內(nèi)的多種文本格式捶箱。
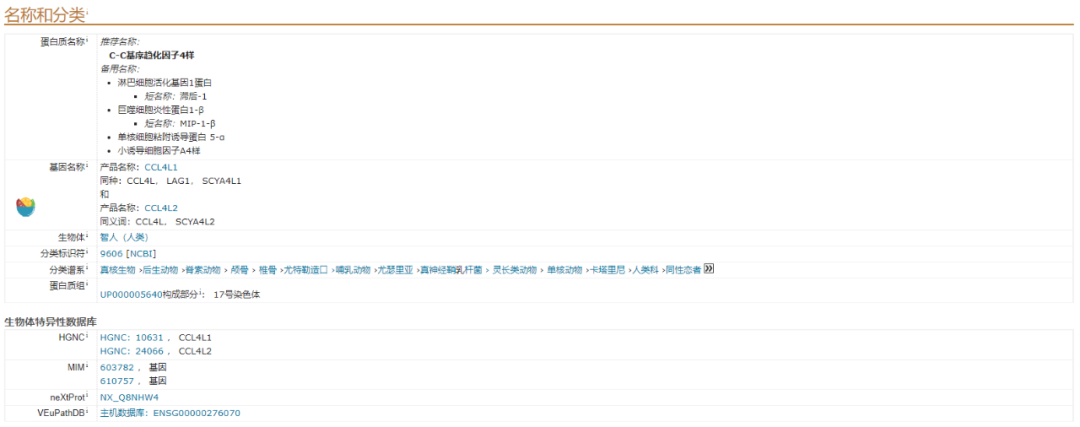
Names & Taxonomyi
對(duì)于科研試劑銷售工作者來(lái)說(shuō)趋肖,用的比較多的是這個(gè)板塊,該板塊展示的是命名(其中包括蛋白名,基因名)和來(lái)源種屬信息乍询,如需要可以直接跳轉(zhuǎn)到NCBI铅惋、Enzem數(shù)據(jù)庫(kù)進(jìn)行查詢。
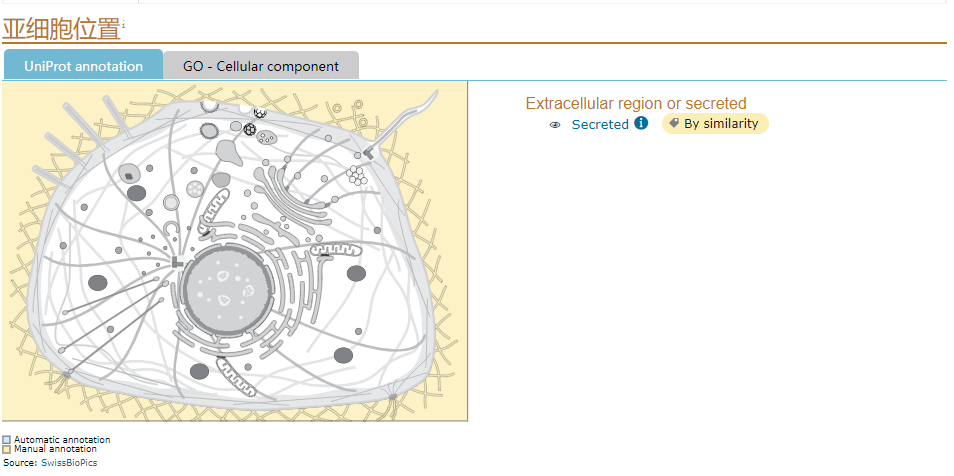
Subcellular locationi
之后是蛋白的亞細(xì)胞定位和拓?fù)浣Y(jié)構(gòu)椰锹±崂模可以看到CCL4L2 是位于細(xì)胞膜外的分泌蛋白
PTM / Processingi
在PTM部分,列舉著蛋白合成過(guò)程中啰蹲,分子加工园凫,氨基酸修飾及翻譯后修飾,比如剪切懒竖、糖基化滚曾、脂酰化蟹幔、二硫鍵位置等信息制依,可以了解到此蛋白的信號(hào)肽序列,和前體蛋白并加以列出惨奕。
Sequences (10+)i
序列這部分是科研工作者需要的重要信息雪位,此部分列出了蛋白從信號(hào)肽開(kāi)始的完整序列,如果該蛋白有不同的剪切體梨撞,各剪切體的序列也會(huì)一一列出雹洗。方便研究者取用。

今天Uniprot數(shù)據(jù)庫(kù)的使用就介紹到這里卧波,希望對(duì)您的科研有所幫助时肿!

 返回列表
返回列表
在線咨詢
Online consultation
-
 在線咨詢
在線咨詢
-
 技術(shù)支持
技術(shù)支持

關(guān)注微信公眾號(hào)

